Waarom legitieme toegang óók een datalek kan worden
- Ward van der Linden
Neem de berichtgeving rond de Odido-breach van februari 2026.
Niet omdat dit incident uniek zou zijn, maar juist omdat het laat zien hoe modern datalek-risico er vaak uitziet: niet als een spectaculaire zero-day in een core-systeem, maar als misbruik van geldige toegang.
Volgens publieke berichtgeving gebeurde de inbraak in twee stappen: eerst werden via phishingmails inloggegevens van klantenservicemedewerkers buitgemaakt. Daarna belden de aanvallers diezelfde medewerkers, deden zich voor als de IT-afdeling, en lieten ze de MFA-prompt goedkeuren. Vanaf dat moment hadden ze toegang tot het Salesforce CRM van Odido. Daar werd ongeveer 48 uur lang doorheen gescrapet — gegevens van zo'n 6,2 miljoen klanten.
En vanaf dat moment wordt het interessant.
Want technisch lijkt veel dan correct.
Een actor is ingelogd.
Autorisatie slaagt.
De applicatie doet wat hij moet doen.
De API geeft netjes
200 OK.
Maar ondertussen kan de hoeveelheid blootgestelde data per minuut blijven groeien.
Dat is het echte probleem van dit soort incidenten: veel systemen controleren goed of iemand toegang heeft, maar nauwelijks hoeveel gevoelige data iemand ziet nadat toegang is verleend.
Een request kan legitiem zijn. Het gedrag over tijd misschien niet.
Toegang is niet hetzelfde als datagebruik
De meeste moderne applicaties hebben de basis redelijk op orde.
We hebben authenticatie:
Wie ben je?
We hebben autorisatie:
Wat mag je?
We hebben audit logging:
Welke actie is uitgevoerd?
Maar bij data-exfiltratie is er nog een andere vraag:
Hoeveel gevoelige data ziet iemand eigenlijk, over tijd?
Een medewerker kan terecht toegang hebben tot klant- of studentgegevens. Een supportmedewerker moet kunnen zoeken. Een administratief medewerker moet lijsten kunnen openen. Een planner moet door records kunnen bladeren.
Op requestniveau is dat allemaal legitiem.
Maar wat als diezelfde gebruiker in korte tijd honderden pagina's doorloopt? Wat als één actor in een uur duizenden unieke personen ziet? Wat als iemand systematisch door pagination heen loopt?
Dan is de vraag niet meer alleen:
Mag deze gebruiker dit endpoint aanroepen?
Maar ook:
Past deze hoeveelheid data nog bij deze gebruiker, rol en context?
Requests zijn een slechte proxy voor data exposure
Een request zegt verrassend weinig.
Eén request kan nul records teruggeven. Of één record. Of twintig. Of duizend. Of een exportbestand met honderdduizend rijen.
Toch behandelen veel systemen requests alsof ze een redelijke proxy zijn voor risico.
Dat zijn ze niet.
100 requests betekent niet 100 records.
En 100 records betekent niet automatisch 100 unieke personen.
Een gebruiker kan honderd keer hetzelfde dossier openen. Dat is ander gedrag dan honderd pagina's met telkens twintig nieuwe personen.
Voor data-exfiltratie is dit onderscheid essentieel. Het risico zit niet alleen in verkeer. Het risico zit in exposure.
Wat je eigenlijk moet meten
We zijn als industrie erg goed geworden in observability. We zijn extreem goed geworden in controleren wie er binnen mag. We zijn nog steeds belabberd in controleren wat er daarna allemaal mee naar buiten gaat.
We meten requests per seconde, latency, error rates, CPU, memory, database queries, queue lag, uptime en p95/p99 response times.
Security monitoring kijkt vaak naar login failures, MFA-events, token misuse, privilege changes, verdachte IP-adressen en admin acties.
Dat is allemaal nuttig.
Maar één fundamentele vraag blijft meestal onbeantwoord:
Hoeveel data over mensen wordt er eigenlijk opgehaald?
Niet hoeveel HTTP requests. Niet hoeveel schermen. Niet hoeveel API calls.
Maar:
hoeveel records
hoeveel unieke personen
welke gevoelige velden
welke actor
welke actie
welke periode
Dat is een andere manier van kijken.
In plaats van:
GET /api/v1/students?page=23&size=20 -> 200 OKwil je ook kunnen zien:
{
"actor": "employee_42",
"action": "student.search",
"resource": "student",
"records_per_hour": 460,
"unique_subjects_per_hour": 460,
"pagination_depth": 23
}De eerste log vertelt dat een endpoint werkte.
De tweede vertelt hoeveel data-exposure er is ontstaan.
Dit type meting bestaat overigens in enterprise DLP- en UEBA-tooling, maar zit zelden op API-niveau in je eigen SaaS, CRM of backoffice.
Een interne Proof of Concept: PII Guard
Bij Ruddur bouwen we systemen waarin operationele data, klantdata en compliance samenkomen. Toen we hier intern over nadachten liepen we tegen deze vraag aan:
Kunnen we niet alleen toegang controleren, maar ook datagebruik meten?
Om dat concreet te maken hebben we bij Ruddur een kleine proof of concept gebouwd: PII Guard.
Niet als groot product. Niet als silver bullet. Gewoon als experiment om te kijken of deze manier van meten nuttige signalen oplevert.
Het idee is simpel:
Inspecteer API-responses.
Tel hoeveel records worden teruggegeven.
Bepaal hoeveel unieke subjects daarin zitten.
Houd dat bij per actor, actie en tijdvenster.
Geef een risk score en reason codes terug.
In veel systemen is een subject
bijvoorbeeld een klant, student, patiënt, medewerker, gebruiker, kandidaat of dossier.
Een fictieve decision-log kan er zo uitzien:
{
"decision": "allow",
"risk_score": 54,
"total_records": 20,
"records_per_hour": 460,
"unique_subjects_per_hour": 460,
"pagination_depth": 23,
"reason_codes": [
"HIGH_RECORD_COUNT",
"HIGH_UNIQUE_SUBJECTS",
"UNUSUAL_PAGINATION_DEPTH"
]
}De request is technisch normaal.
Het gedrag is dat misschien niet.
Context bepaalt of volume verdacht is
Volume alleen zegt weinig. Een integratie kan duizenden records per uur synchroniseren zonder dat dit verdacht is, terwijl hetzelfde gedrag bij een individuele medewerker juist wél kan opvallen. Daarom moet data-exposure altijd worden beoordeeld tegen de juiste context: rol, actor-type, actie en tijdvenster.
roles:
support_agent:
suspicious:
records_per_hour: 100
unique_subjects_per_hour: 100
step_up:
records_per_hour: 750
unique_subjects_per_hour: 750
integration:
suspicious:
records_per_hour: 5000
unique_subjects_per_hour: 5000Een score zonder uitleg is beperkt bruikbaar. Reason codes maken zichtbaar waarom gedrag opvalt.
{
"risk_score": 55,
"reason_codes": [
"HIGH_RECORD_COUNT",
"HIGH_UNIQUE_SUBJECTS",
"UNUSUAL_PAGINATION_DEPTH"
]
}Daarmee zeg je niet alleen: “score 55”, maar: deze actor heeft veel records gezien, veel unieke personen geraakt en opvallend diep door pagination gebladerd.
Ook niet alle records zijn gelijk. Twintig productrecords zijn iets anders dan twintig personen met e-mailadressen, telefoonnummers, adressen of geboortedata. Daarom wil je naast volume ook gevoeligheid classificeren.
Zo kun je onderscheid maken tussen veel data en veel gevoelige data.
Mogelijke responses
Als je dit soort signalen hebt, kun je verschillende dingen doen.
Niet alles hoeft meteen hard blocking te zijn.
Dit lijkt op rate limiting, maar dan op data-exposure in plaats van requests.
Loggen: leg data-exposure vast zonder gedrag te veranderen.
Alerting: waarschuw security of operations wanneer gedrag buiten de baseline valt.
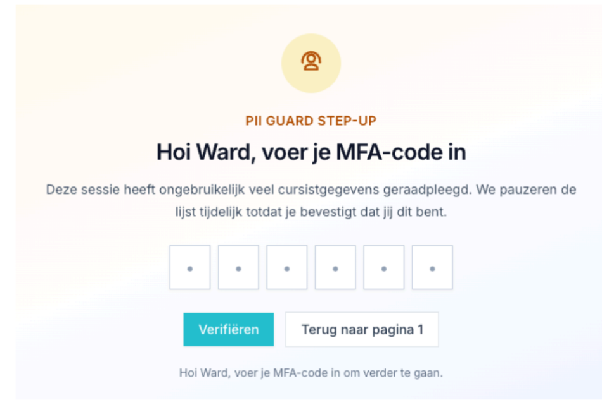
Step-up: vraag extra verificatie, bijvoorbeeld MFA, voordat meer data wordt getoond.
Throttling: vertraag of beperk verdere lijst- en exportacties.
Masking: toon minder gevoelige velden zodra het risico oploopt.
Blocking: blokkeer alleen bij extreem gedrag of duidelijke policy-overtredingen.
Een volwassen aanpak begint meestal met observeren. Daarna kun je stapsgewijs meer doen. Maar let wel, dit soort systemen kunnen snel te agressief worden. Daarom is context belangrijk. Begin in observe mode, vergelijk per rol en actor, gebruik reason codes en meet eerst een paar weken voordat je handhaaft.
PII Guard zelf kijkt naar gevoelige data om gevoelige data te beschermen. Dat vraagt om een eigen governance-laag: minimalisatie van wat opgeslagen wordt, korte retentie van decision logs, en duidelijke scheiding tussen exposure-meting en operationele data-toegang. Anders verplaats je het probleem alleen.
Waarom dit relevant is voor SaaS, CRM, HR, zorg en backoffice
Elke applicatie met persoonlijke of klantgerelateerde data heeft dit probleem.
CRM-systemen. HR-systemen. Zorgsystemen. Financiële portals. Supporttools. Backoffices.
Overal waar mensen door lijsten met personen kunnen zoeken, filteren, exporteren of bladeren, bestaat dit patroon.
Voor moderne SaaS-systemen zou data-exposure daarom een normale observability-vraag moeten worden.
Niet alleen:
Werkt het endpoint?
Maar ook:
Hoeveel gevoelige data stelt dit endpoint bloot, voor wie, en over welke periode?
Want zodra er iets misgaat, is “het endpoint werkte” niet meer de vraag. Dan moet je kunnen reconstrueren welke actor, in welk tijdvenster, welke persoonsgegevens heeft ingezien voor de AP, voor een rechter en voor je klanten. Zonder die data bouw je je incident response op schattingen, en schattingen zijn juridisch en reputationeel duur.
Bij Odido draaide het scrape-window ~48 uur. In die periode was er geen technisch alarm — want technisch klopte alles. Met data-exposure als first-class meetwaarde was er minstens een signaal geweest. Of dat signaal genoeg was om het tegen te houden, weten we niet. Maar zonder dat signaal weten we wél dat er niets is dat het kan tegenhouden.